I just put up a wiki page with an example of adding titles to related-links > linkpools (that’s mouthful, and a strange one at that:)) in DITA. This solution exposes the little known, and perhaps less used, markopen attribute in default.wwconfig. (more…)
Archive for the ‘Uncategorized’ Category
Related Links (DITA)
WebWorks FTP Deployment (Experimental)

We just posted an application and wiki entry for a new experimental FTP deployment client for ePublisher. Anyone interested in using FTP(S) for deployment, please give it a go and give us feedback. Please comment either on the wiki page or this blog post.
Study Hall Makeup
Today I completely spaced on a Study Hall session that was to occur at 3:00pm CDT. To make amends, I have scheduled a make-up session for Thursday, May 13 at 1:00PM.
Building New Stuff
One of the things that is challenging for me as a developer is staying on target with regard to ePublisher development when there are so many glittery web-technologies to play with. For example, I have have long yearned for a true AutoMap server which would allow for the Administration of ePublisher/AutmoMap configuration and execution over a web (http) connection. Recently I put together a Google Docs input adapter with the intention of demonstrating the capabilities of the ePublisher architecture. When it comes to inputs, I’ve got far more ideas than I have time to implement.
ru2k9
I had meant to blog about coming to RoundUp last week…and then I didn’t. So, for those of us who are here anyway, wow! What a good conference. In the interests of disclosure I will good ahead and let you know that I’m going to gush a little. Yesterday gets my vote for the all-time best RoundUp day ever. The panels (the one I saw:)) were fluid, effective, informative.
Boot Camp
The Boot Camp room, where I was set up for all but one panel, was good. I demoed a transformer server that we used as a teaching tool and this seemed to go really well. The main purpose of the tool is to provide an online XSL Transform to evaluate XPath, try out transformation scenarios; basically, play with XSL right away without and run-time set up.
Case Studies and Presentation
The case studies and presentations have been really good. That’s admittedly a tepid comment, given that it uses “really” qualifier. But I am sincere. In the case of both morning presentations, Stewart Mader and Tom Johnson, both gave effective presentations…and I disagreed with a lot of their ideas. This is hardly surprising, given that I find nearly all opinions which are not my own, at least minorly offensive in some way. I also feel that precisely because I disagreed with their opinions so strongly (at least in Tom’s case), the presentations were highly effective. Perhaps at another time I will blog about what chaffed.
**POSTSCRIPT-ish** OK, I’ve now talked to three different people about my strong disagreements and I’m convinced that this is my own trip. Ben made the point that when I questioned Tom today after the session, it was as if I felt, he were talking directly to me. Touched a nerve. Anyway, great presentation Tom, for real.
Booze Cruise
So at the end of the magical first day, we had a cruise out on Ladybird Lake (formerly known as Town Lake (when did that happen? (i’m writing recursive asides, i’m such a programming nerd!!))). The weather was that one-of- two days-of-perfect-72-degree-weather-a-year in Austin. At the tail end of it, in the sun setting sky, the bats came spewing out of the Congress Avenue bridge just as the boat took our happy party beneath it. Sweetness.
Manyana
Some great stuff has turned up at RoundUp this year. I’m a little jealous of the folks like Mary Anthony and Liz Keene and Jae Evans, with whom I did a panel on Monday, when I hear about all of the cool stuff they’re doing with ePublisher. It may seem that I’m blowing smoke up my own or our collective company’s wazoo, but the fact is, I love to tinker and when ePublisher is at its best, it’s like a muscle car that you tinker with and that’s what these folks are doing. Tomorrow some of the attendees will get to showcase some of what they’ve done while here. Also, we have a neat demo waiting in the wings that I’ll blog about more at a later time.
And at a little after noon tomorrow, it’s over, quick as it started, with scarcely a ripple showing in the busy downtown Austin bustle, with a release bearing down, and with a defiant and lingering joy or buzz or both.
ePublisher Feed Reader
Shortly after the release of 2009.2, and after some cooperative discussion here on ways that we might improve ePublisher moving forward, I started work on a Feed Reader for the ePublisher Start Page. This isn’t that ground-breaking as a Feed Reader seems to be fairly commonplace on a start or splash page. The first iteration simply listed the feed items and allowed you to view the entry in your default browser.
This was good progress, but we wanted to see if we could open the blog entries directly in ePublisher, as is the case in Visual Studio. This turned out to be not too difficult to implement. I think it’s cool that a fairly minor augmentation could change the way I think about ePublisher. We’ve always had the ability to view HTML in ePublisher, though the only current place that we use this capability is in the Preview. Opening up ePublisher to allow for browsing the web at-large caused a small cascade of ideas, which I will mention in a later post.
I’m including a couple of screen captures. I am completely to blame for the colors, whether you like them or you don’t. Thoughts?

Start Page with feed reader

Feed link open in ePublisher Pro
Page Template Preview Utility
As promised at RoundUp, I have posted a wiki article on the Page Template Preview utility. It lacks a number of things, such as good design, a clearly defined objective, among others. However, it was fun to write and I hope that it might be useful to anyone who may be trying to unravel Page templates.
Publishing Content From the WebWorks Wiki
One of the more interesting aspects of the ePublisher 9.3 Release is the introduction of the Xml Adapter. By default, this Adapter allows users to generate output from DITA source documents. However, perhaps more significantly, it carries with it the ability to configure ePublisher to accept ANY input source.
To demonstrate this functionality, during RoundUp 2007, we showed the Xml Adapter publishing content from the WebWorks Wiki to WebWorks Help 5.0. It was our intention at that time to make this project available online. With this objective in mind, I’ve added a page in the RoundUp section of the WebWorks Wiki. This page includes the project I used to publish content during the Day 2 Keynote. It also includes instructions for modifying which WebWorks Wiki content is included in the project. This effectively gives you the ability to create your own WebWorks Help 5.0 help system, or any other ePublisher supported output Format, including ones you have developed, using content from the WebWorks Wiki.
In the coming weeks, I plan to publish a tutorial on developing a custom Xml Adapter from scratch. Stay tuned.
FrameMaker 8 Conditional Expressions
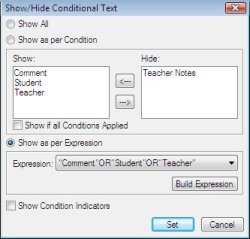
Figure: FrameMaker 8’s Show Conditional Text as per Expression
Currently, we are working on updating ePublisher to run on Windows
Vista. Also I am working on updating ePublisher’s FrameMaker Tool
Adapter to support FrameMaker 8. One of the more challenging
aspects of this latter task is adding support for FrameMaker 8’s new
“conditional expression” feature. This feature allows the end user
to define a logical expression which should be used when applying
visibility settings to conditional segments of a FrameMaker document.
On the FrameMaker side, it seems that retrieving the information
from the new FDK is relatively trivial. The more interesting
challenge may be how to present this new paradigm to ePublisher
users. At first we decided to wrap the old mechanism in a radio
button region, and add the new option to a new radio button section.
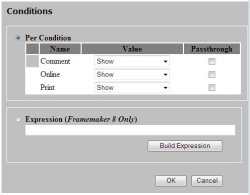
Figure: HTML Mock-up of Radio Button Approach
Initial efforts to design this approach have fleshed out an
important shortcoming in the current “unified” interface that
ePublisher presents for defining condition visibility. Specifically,
different source formats have different ideas of what “conditions”
are and how they are implemented. DITA provides a “tag-like”
approach which allows filtering for purposes other than visibility.
If your input is Word or a version of FrameMaker below 7.x, you have
no use for an expression option.
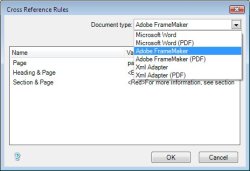
Figure: ePublisher’s Cross Reference Rules Dialog
This revelation is causing us to pursue an alternative approach. The
idea is to move Conditions out of the hybrid Conditions/Variables
dialog, altogether, and model a new Conditions dialog, after the
existing Cross Reference Rules dialog. As with Cross Reference Rules,
this approach would allow us to display a Conditions dialog
appropriate for each input format. No mock-up yet, but stay tuned.
process soup
Ingredients
- I have a tendency to want to write a program first and design it later. Given that my academic background is not computer science, I often feel that I'm missing something about spec writing, design, etc. And I am. I believe that the penultimate of hubris, a path I traverse more often than I would care to admit, is to make any emphatic statement about a thing for which one has little or no first-hand knowledge.
- Recently, one of my fellow developers gave a presentation on UML and highlighted the differences between forward and reverse modeling. Reverse modeling builds an abstract representation from an existing implementation. Forward modeling is the opposite. Build the model first, write the code second. Both are valid approaches to modeling.
- Last Tuesday I attended the Agile Austin meeting with Ben. One thing which really resonated was the speaker's assertion that you need to shape a work flow to suit your process. As with any evolutionary system, there must be room to specialize.
- In film, there is a certain time of day, around the sun's rising and setting, when the natural lighting is ideal, which is referred to as the “magic hour”. On a shoot, entire days and weeks of preparation may be all centered on getting a few seconds in the can during this small window.
- Last week I read this blog entry by Joel Sposky. In this entry he writes (and I'm pulling this quote out of context, so I highly recommend that you read the entry, though for the sake of brevity, I will summarize the context as: a statement on the relationship between a software spec and the resulting program):
…the bottom line is that if there really were a mechanical way to prove things about the correctness of a program, all you’d be able to prove is whether that program is identical to some other program that must contain the same amount of entropy as the first program, otherwise some of the behaviors are going to be undefined, and thus unproven. So now the spec writing is just as hard as writing a program, and all you’ve done is moved one problem from over here to over there, and accomplished nothing whatsoever.
Soup:
So my tendency to want to build first, design later, may not be entirely misguided. It seems to me that the real trap here, is the “which is better” conundrum. Both may be valid. This soup is about the way I prefer to program, which may be summarized in the following order:
- Spend a little bit of time thinking about what I want to write. If someone else is coming up with the idea, spend a little bit of time brainstorming with them. DON'T WRITE ANYTHING DOWN YET.
- Implement the brainstorm immediately. Within a few days, or a week.
- Analyze the result (document and model; often this ends up in a readme) and recurse.
Some things to note about this process. First, the post-brainstorm implementation implies a managable chunk. It's not to say that you can't build large apps. But build incomplete representations of the large app first.
For instance, if you're going to write a classic MVC app and each aspect will probably require several weeks to implement, then the first offering might be a simple glue code program which interacts with stubs that print statements about the “real” code that should ultimately exist there. That is, if a controller needs to do a series of complex database operations, then in the initial version, the controller will print a message like, “doing complex database operations…”.
The point is, nothing should derail the programming “magic hour” which follows a good brainstorming session. Things can be refactored and analyzed later. In the beginning, generate velocity. Ultimately the resulting intertia can be much more easily molded into the desired result. But as with bicycles and sailboats, it is very hard to steer a thing which has no motion, or in programming, doesn't do anything.
Cleanup:
This, by the way, IMO is the primary reason for the ubiquity of Hello World.
Obviously, this article is mostly outloud thinking about my own process. It's unoriginal, plagiarist and derivative. It's specialization.